英伟达发布H200, 高性价比全面升级
在11月13日的S23大会上, NVIDIA 宣布推出NVIDIA HGX H200,为生成式人工智能和高性能计算(HPC)工作负载提供强大支持。
根据介绍,新的H200 GPU是当前H100的升级产品,作为第一款搭载 HBM3e 的 GPU,H200 集成了141GB的内存,更大更快的内存推动生成式人工智能和大型语言模型(LLM)的加速,同时推进科学计算在 HPC 工作负载中的发展,在用于推理或生成问题答案时,性能较H100提高60%至90%。
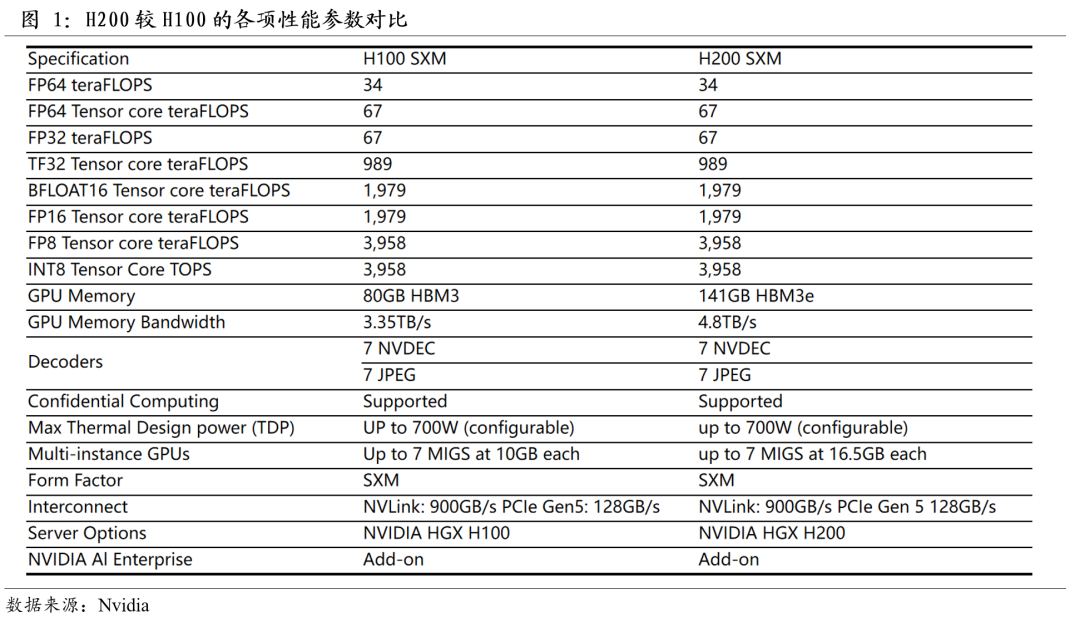
H200主要在内存带宽和内存容量上进行提升
为了最大化计算性能,H200 是全球首款搭载 HBM3e 内存的 GPU,拥有4.8TB/s的内存带宽,较 H100 增加了1.4倍。H200 还将 GPU 的内存容量扩展到141GB,几乎是 H100 的80GB 的两倍。更快速和更大容量的 HBM 内存的结合,加速了计算密集型的生成式人工智能和高性能计算应用的性能,同时满足了不断增长的模型大小的需求。对比 H100 和 H200 的性能参数,在算力指标上H200和H100完全一样。H200 的所有改进都集中在更快速和更高容量的141GB HBM3e 的引入。
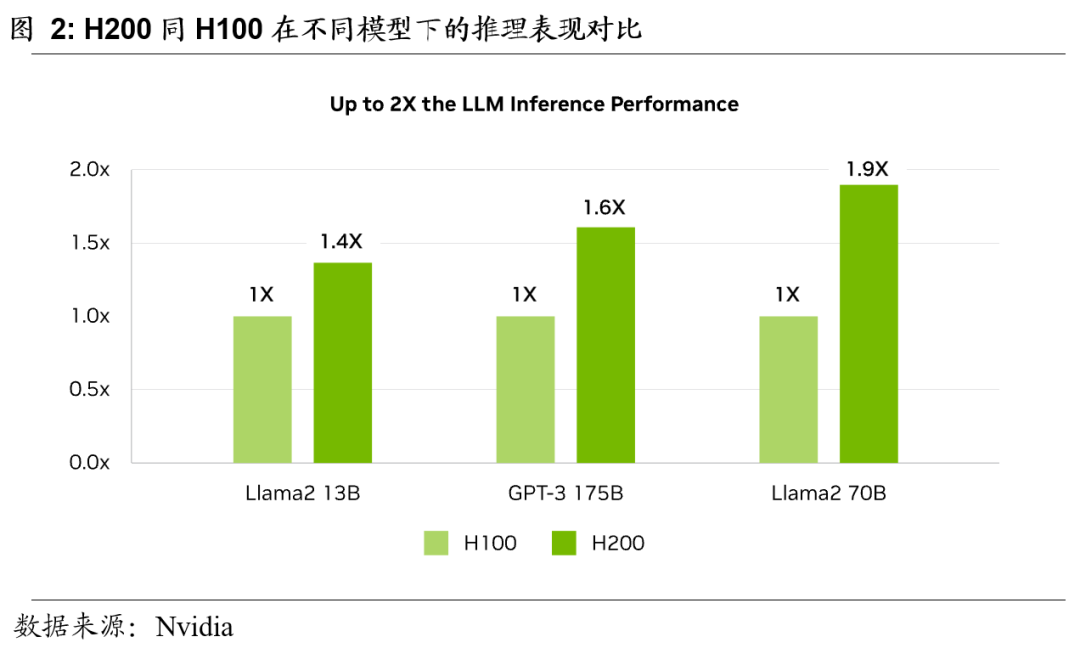
H200相较于H100在推理性能上最高提高至2倍
H200的推理表现相较于H100在各大不同的模型都具有明显的提升。与处理类似 Llama2(一个 700 亿参数的 LLM)的LLMs时相比,相较于 H100 GPU,H200 在推理速度上提高了最多 2 倍。
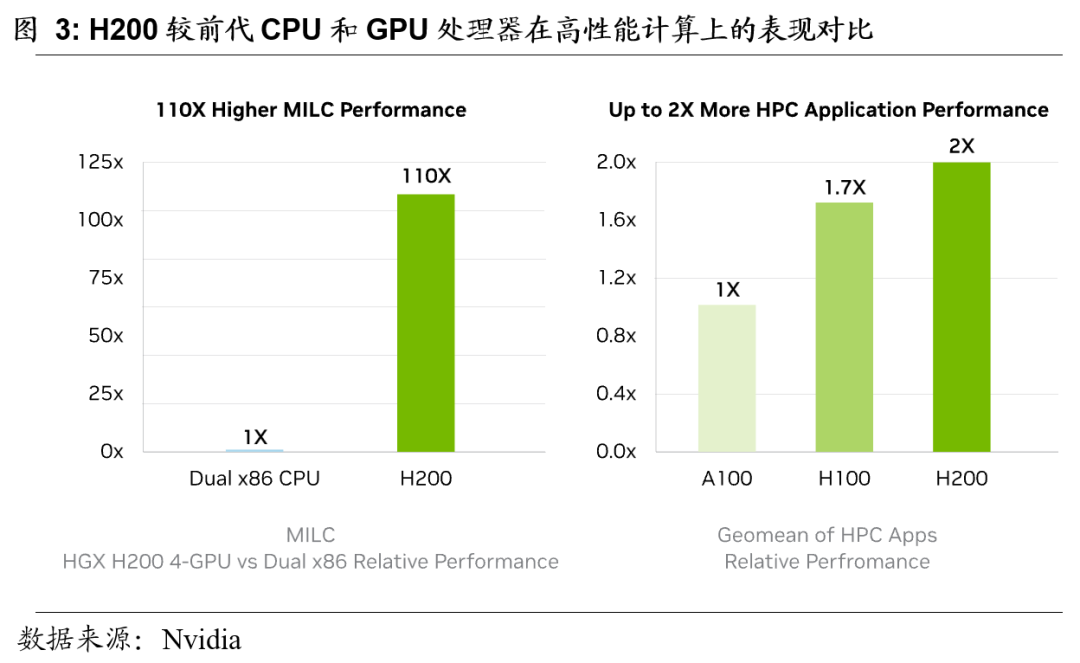
高内存带宽激发高性能计算表现
内存带宽对于高性能计算应用至关重要,因为它能够实现更快的数据传输,减少复杂的问题处理。对于内存密集型的高性能计算场景,如仿真、科学研究和AI,H200 的更高内存带宽确保数据可以被高效地访问和操作,从而在与 CPU 相比,实现高达 110 倍更快的生成结果时间。
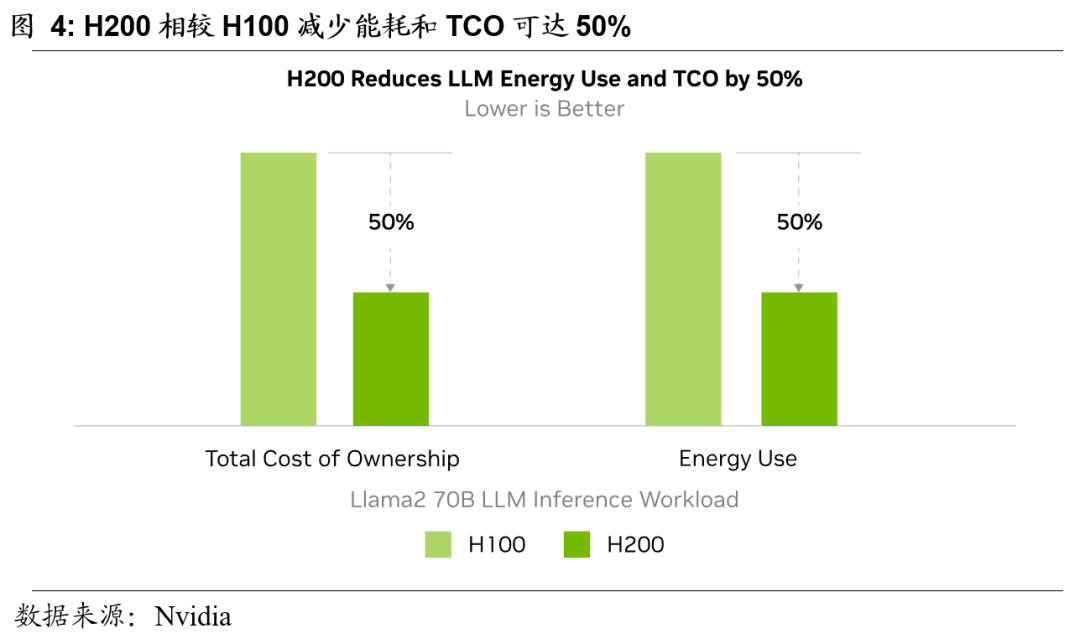
降低能耗和总拥有成本(TCO)
H200 的引入使得AI数据中心能源效率和TCO进一步提升。H200在性能相较H100具有明显提升的背景下,保持了与 H100 相同的功耗。以Llama2 70B这样的模型去推理衡量看,H200的性能是H100的两倍,在功耗相同的情况下,成本是原来单位成本的一半。