cache的物理结构
教材上通常介绍的cache就是直接映射,组相联和全相联。
如下图所示
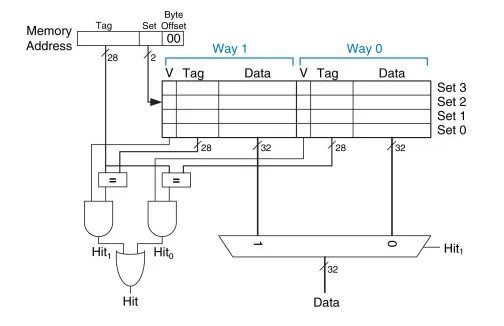
那么cache真实的物理层面物理结构是什么样的呢?
bank
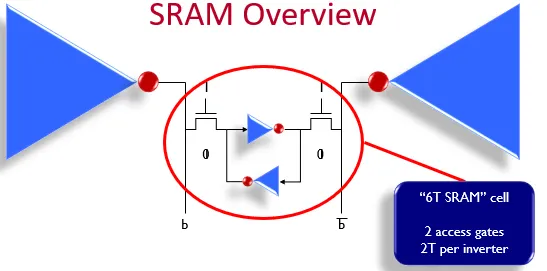
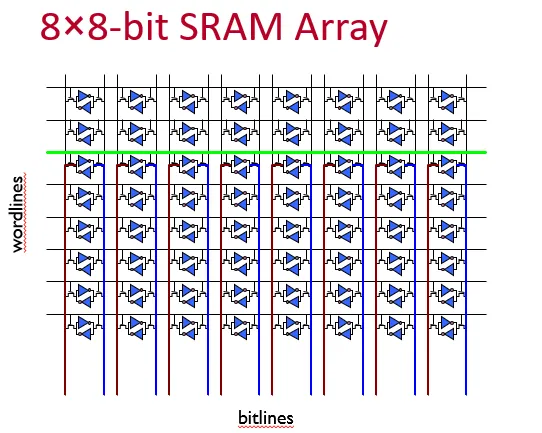
cache是由SRAM实现的,通过wordline选中,从bitline输出。
L3 cache可能需要在同一个时钟周期处理多个请求,于是需要增加多个读写端口。如果只是增加wordline和bitline,如下图所示,
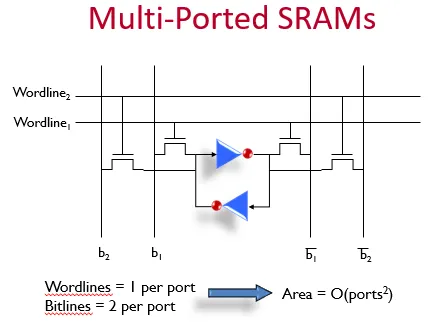
那么SRAM的面积会随着端口的二次方增长。
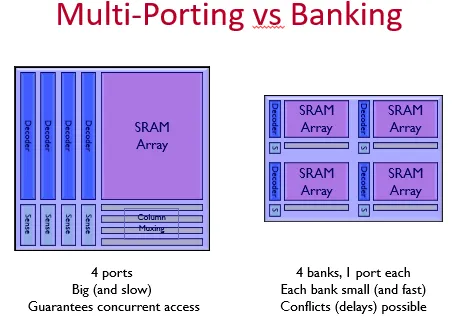
随着SRAM面积的增加,SRAM的延迟也会增加,big and slow。
为了支持对cache的同时多个读请求,我们可以interleaved的形式将cache切分成多个bank。

注意上图中的index+bank替代了传统的index,在物理地址上连续的block地址,索引不同的bank。
这样如果cpu同时对连续的地址发出请求,就可以同时向不同的bank发出请求,返回响应。
timing
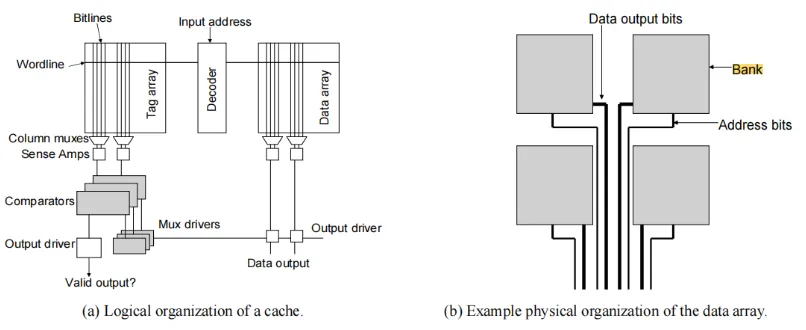
决定cache的延迟的因素:
- senseamp 和 comparator 延迟是常量,不随cache size 变化
- driver delay 随着cache的增加成比例增加
- decoder的延迟包括了将address route到center predecoder,将precoder route到 final stage decoder的路由延迟和逻辑延迟。decoder的延迟取决于cache size和sram subarray的数量。
- wordline delay和bitline delay,sram subarray,wordline和bitline delay越大。
subarray-size越小,那么wordline&bitline delay越小。但是因为此时subarray的number就要增加,于是route的delay也就增加。
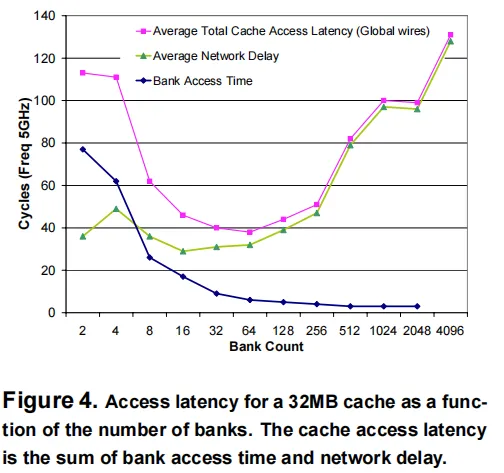
在cache大小相同的情况下,也就是切的bank越多,访问bank内部的时间越少,但是花在路由上的时间越多,如上图所示。
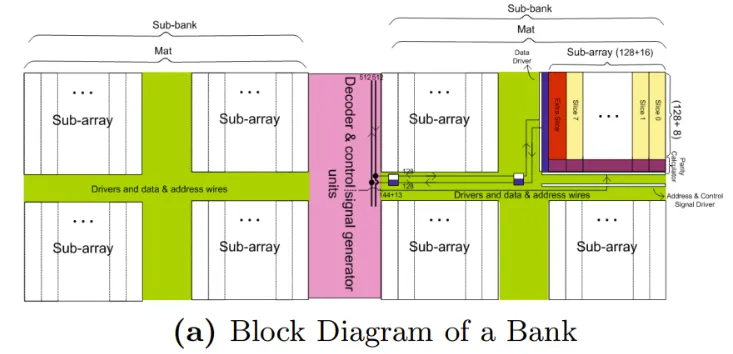
subbank
如果同时有4个地址请求,那么在请求不发生bank conflict的条件下,可以同时访问4个不同的bank。同一个bank不允许同时处理多个请求。

如上图所示,bank内部分为subbank,subbank内包含多个mat。
一个mat包括4个subarray,subarray之间共享central predecoder。
如果需要响应cacheline 64byte的请求,那么是subbank内的所有mat同时响应,每个mat负责处理一部分。如下图所示,红色虚线方框即为一个mat,每个mat处理16byte,4个mat处理一个64byte。
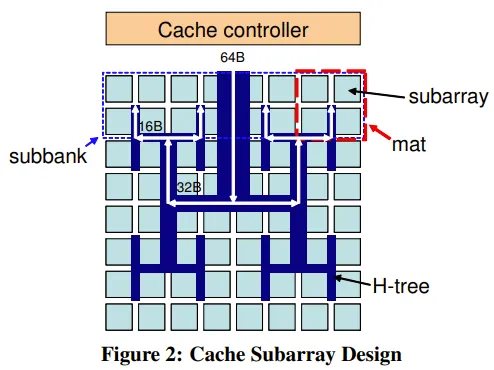
mat中选中的那个subarray返回128bit。如下图所示:
nuca
随着cache size的增加,因为走线延迟的增加,越靠近读写端口的SRAM的延迟越小,越靠近远端的SRAM延迟越大。
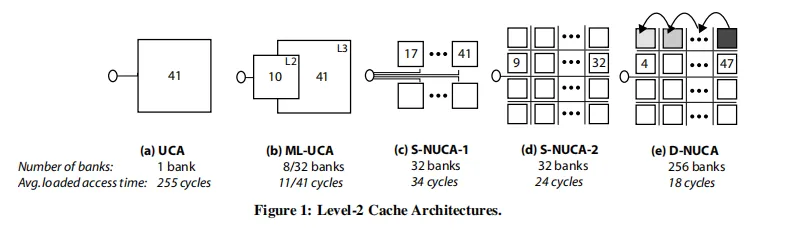
如上图d)所示,最靠近读端口的sram只需要9个cycle,最远的则需要32个cycle。
不同的sram bank延迟不同的架构被称为non-uniform cache structure。
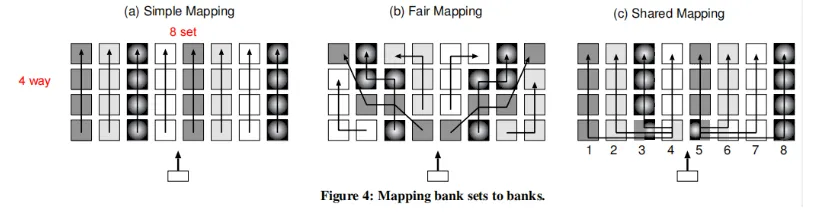
上图是一个4路组相联cache,一共32个bank。有三种映射方式:
simple mapping,简单,缺点是不同的set的延迟不同,越靠近读端口的那个set的延迟越小。同时,同一个set内,越靠近读端口的那一way的延迟越小。
fair mapping,不同的set的平均延迟相同
shared mapping,将最靠近读端口的sram平均分配给各个set。
文中插图出处:
[1] An Optimized 3D-Stacked Memory Architecture by Exploiting Excessive, High-Density TSV Bandwidth [2] CACTI 6.0: A Tool to Understand Large Caches [3] CACTI 3.0: An Integrated Cache Timing, Power, and Area Model [4] Flexicache: Highly Reliable and Low Power Cache [5] Best Memory ArchitectureExploration under Parameters Variations accelerated with Machine Learning [6] A Shared Polyhedral Cache for 3D Wide-I/O Multi-core Computing Platforms [7] 4-Port Unified Data/Instruction Cache Design with Distributed Crossbar and Interleaved Cache-Line Words [8] Unified Data/Instruction Cache with Bank-Based Multi-Port Architecture [9] The Effect of Interconnect Design on the Performance of Large L2 Caches [10] An Adaptive, Non-Uniform Cache Structure for Wire-Delay Dominated On-Chip Caches