Remote Direct Memory Access (RDMA) is a key technology in High-Performance Computing (HPC), enabling ultra-fast and efficient data transfer between compute nodes. With RDMA over Converged Ethernet v2 (RoCEv2), organizations can achieve low-latency, lossless communication across data centers and AI workloads.
This article explains how RDMA works step-by-step — from memory registration to RDMA write operations — with diagrams to help you understand the process.
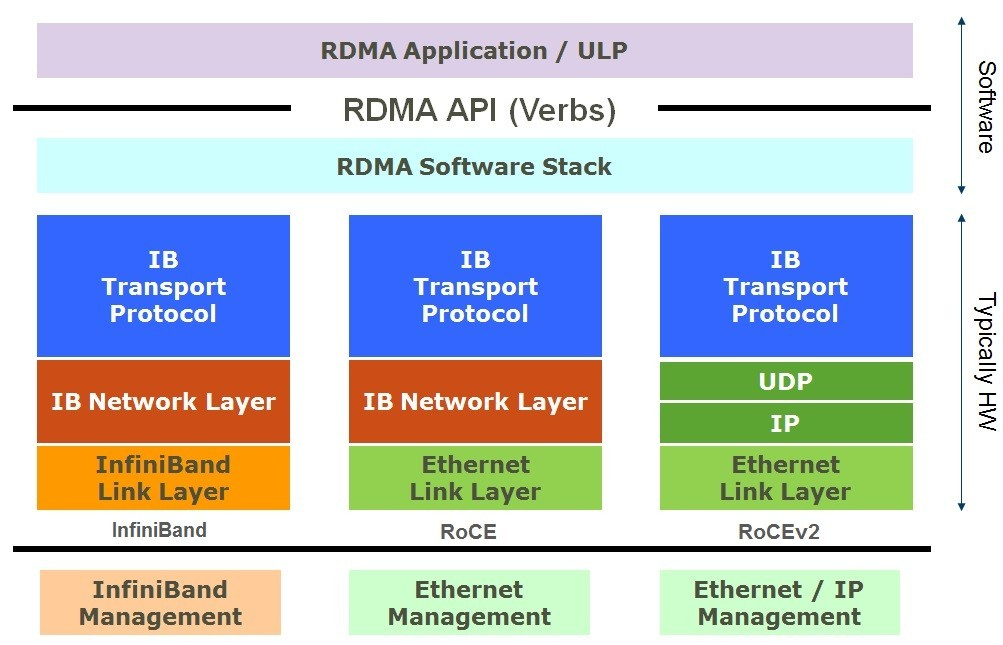
Figure 1: Fine-Grained DRAM High-Level Architecture
What is RDMA and Why It Matters? #
RDMA allows direct access to memory on remote systems without involving the CPU or OS, which significantly reduces latency and improves bandwidth efficiency. This is critical for:
- AI and machine learning training (fast dataset transfer)
- High-performance computing clusters (efficient inter-node communication)
- Data-intensive workloads like real-time analytics, NVMe-over-Fabrics, and distributed storage
RoCEv2 uses UDP transport, which means it does not handle packet loss due to congestion. To maintain lossless data delivery, modern networks use:
- Priority Flow Control (PFC) – prevents buffer overflow
- Explicit Congestion Notification (ECN) – signals senders to slow down
RDMA Process Overview #
When a client compute node (CCN) writes data to a server compute node (SCN), the process involves four main steps:
- Memory Allocation and Registration
- Queue Pair Creation
- Connection Initialization
- RDMA Write Operation
Each step is explained in detail below.
Step 1: Memory Allocation and Registration #
- Allocate a Protection Domain (PD), similar to a tenant or VRF in networking.
- Register memory blocks, defining size and access permissions.
- Receive keys:
- L_Key (Local Key) for local access
- R_Key (Remote Key) for remote write access
In our example:
- CCN memory → local read access
- SCN memory → remote write access
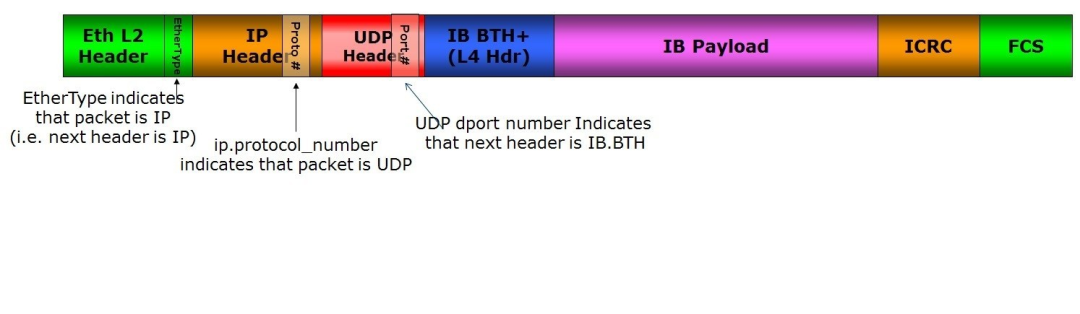
Figure 2: Memory Allocation and Registration
Step 2: Queue Pair (QP) Creation #
- A Queue Pair (QP) = Send Queue + Receive Queue.
- A Completion Queue (CQ) reports operation status.
- Each QP is assigned a service type (Reliable Connection or Unreliable Datagram).
For reliable data transfer, we use RC (Reliable Connection).
- Bind QP to PD and memory region.
- Assign a Partition Key (P_Key), similar to VXLAN VNI.
Example:
- CCN QP ID:
0x12345678 - Associated P_Key:
0x8012
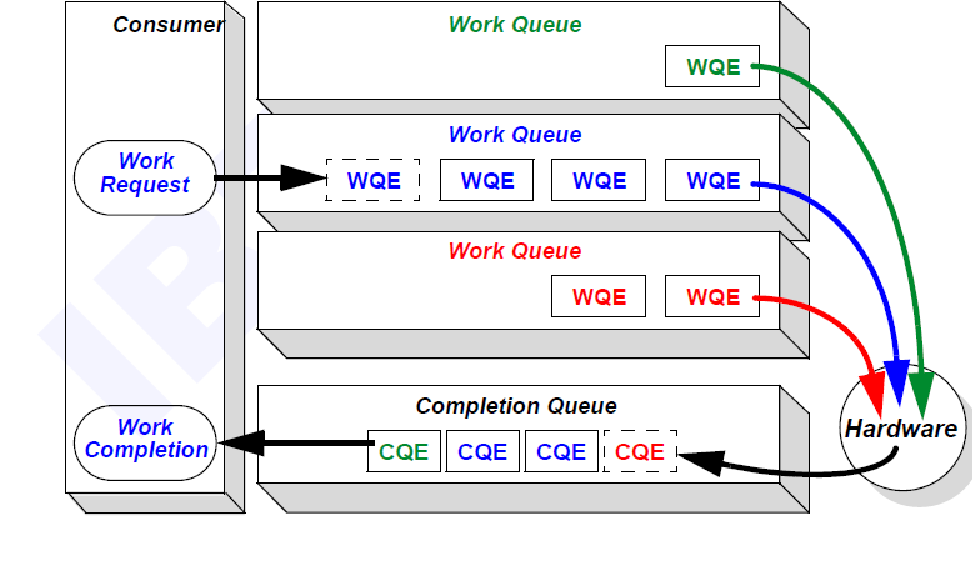
Figure 3: Queue Pair Creation
Step 3: RDMA Connection Initialization #
Connection setup involves REQ → REPLY → RTU messages:
- REQ (Request): CCN sends Local ID, QP number, P_Key, and PSN.
- Reply: SCN responds with IDs, QP info, and PSN.
- RTU (Ready to Use): CCN confirms connection.
At the end, the QP state transitions from INIT → Ready to Send → Ready to Receive.

Figure 4: RDMA Connection Initialization
Step 4: RDMA Write Operation #
Once connected, the CCN application issues a Work Request (WR) containing:
- OpCode: RDMA Write
- Local buffer address + L_Key
- Remote buffer address + R_Key
- Payload length
The NIC then builds the required headers:
- InfiniBand Base Transport Header (IB BTH) – includes P_Key and QP ID
- RDMA Extended Transport Header (RETH) – includes R_Key and data length
- UDP header (port 4791) indicates IB BTH follows
Data is encapsulated and sent over Ethernet/IP/UDP/IB BTH/RETH.

Figure 5: Generating and Posting an RDMA Write Operation
On the SCN side:
- Validate P_Key and R_Key
- Translate virtual to physical memory
- Deliver data to the QP’s receive queue
- Notify application via the completion queue

Figure 6: Receiving and Processing an RDMA Write Operation
Key Benefits of RDMA #
- 🚀 Ultra-low latency data transfer
- ⚡ High bandwidth efficiency for HPC and AI
- 🔒 Bypasses CPU/OS overhead for direct memory access
- 📡 Lossless transport with PFC + ECN
- 🔄 Scalable design for large clusters and data centers
Conclusion #
RDMA technology, especially with RoCEv2 over IP Fabrics, is essential for modern data-intensive workloads. By offloading memory operations from CPUs and enabling direct memory access across compute nodes, RDMA improves performance in AI training, big data analytics, distributed storage, and cloud-scale HPC systems.
Organizations adopting RDMA can expect:
- Faster application performance
- Lower latency in AI/ML pipelines
- Better efficiency in multi-node HPC environments
🔗 Original article: Detailed Explanation of the RDMA Working Process